The Critical Brain Hypothesis
In the spirit of the yearly Society for Neuroscience (SfN) conference, I wanted to clean up and post this review which I have had in the archives for some time. I am publishing this from the Better Buzz coffee shop in San Diego, on the first non-rainy day, and am about to head to the convention center to check out some posters.

The view from my hotel balcony in San Diego (at the Humphreys Half Moon Inn for anyone interested).
This post is a short continuation of the discussion of phase transitions from the previous post. In this post, we review the theory that the brain self-organizes or fine-tunes near the critical point of a second-order phase transition between ordered and disordered states, known as the critical brain hypothesis. We begin by reviewing classical phase transitions, talk about the critical brain hypothesis within this presented framework, and then develop and experimentally study the critical properties of a stochastic branching process that is modeled after recurrent layers of neurons. Finally, we derive the critical exponents of the branching process under a mean-field approximation, and compare them to our in-silico experimental observations and previously published in vivo results.
Introduction
As a quick recap, phase transitions [8] [25] [26] are phenomena first observed in nature, where small changes in a control parameter (temperature, for example) leads to dramatic changes of the quantitative properties or state of an object (the order parameter). Traditionally, the types of phase transitions are categorized into either first-order or second-order phase transitions, called the Ehrenfest Classification [7]. First-order phase transitions undergo a discontinuous change in the order parameter through the phase transition, whereas second-order phase transitions undergo a continuous change. To give a concrete example of this, given the control parameter temperature, and a constant pressure of 1 atm, a liquid will undergo a first-order liquid-to-gas phase transition at the critical temperature of 100 degrees Celsius. This is a first-order transition in the sense that at exactly 100 degrees Celsius there is a discrete change in its properties. Across many dynamical systems that undergo phase transitions, unique properties have been observed near or at critical points including long-range dynamic correlations and scale-free dynamics. For more details, see my previous post.
The critical brain hypothesis [1] [2] [10] [11] [12] [14] [17] [18] [19] [20] [21] proposes that biological neural systems operate at or near the critical point of a second-order phase transition, balanced between ordered and disordered states. One of the reasons it may be advantageous for the brain to either self-organize or fine-tune [2] [9] [15] [16] near criticality is that, from an information-theoretic standpoint, systems at criticality exhibit optimal information transmission, and may even achieve a balance between efficient and generalizable encoding of information [3]. More evidence for criticality in the brain comes from the observation that neuronal avalanches, which are cascades of neural activity that propagate through networks following the characteristic patterns of critical systems, exhibit scale-free dynamics in their relative size and lifetime distributions (which follow power laws). Recent experimental evidence using various recording techniques, from single-neuron measurements to large-scale brain imaging, has revealed signatures of criticality across different scales, including power-law distributions of neural activity, long-range dynamic correlations, and critical fluctuations [1]
There are also three other threads of research in criticality that I find interesting, but will not go too much into. These are: (1) Understanding biologically how the brain could either fine-tune or self-organize near the critical point [13] [15], (2) the clinical relevancy of criticality in the brain [23] [24], and (3) other miscellaneous directions of research that I found interesting [5] [6].
A Stochastic Branching Model
To study and formalize these concepts mathematically, we simulate a stochastic branching process that models the simplified dynamics of activity propagating through layers of neurons. Below is an interactive figure that allows you to simulate the branching process for varying initial conditions and values of the coupling strength .
You can play with this interactive figure to study supercritical brain dynamics by cranking up the value of the order parameter , or subcritical brain dynamics by reducing the value of . The initial sites parameter controls the initial value.
More formally, we consider a network in which individual neurons can activate other neurons through a probabilistic weight matrix. The state of each neuron at time is represented by , indicating whether the neuron is active (1) or inactive (0). Then, let be the conditional probability that neuron becomes active at time given that neuron was active at time . That is
Furthermore, these connection probabilities satisfy the normalization condition
for all source neurons and times . This ensures that the total probability of activation flowing from any source neuron sums to one (see Figure 1 for intuition).
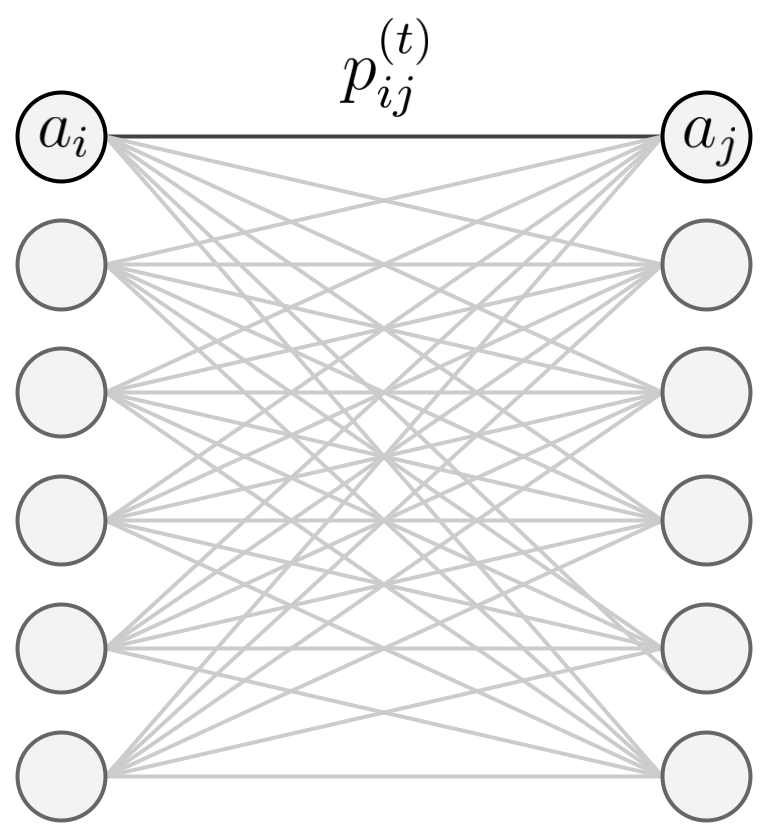
Figure 1: A small illustration of the stochastic branching model. The model is a simple network of neurons that can activate other neurons in subsequent layers through some probability of activation.
Given this framework, we define the update rule for activity propagation as
where is the Heaviside step function, is the coupling strength (control parameter), and are independent random variables uniformly distributed on for each neuron at each timestep.
Expected Value Analysis
In analyzing this branching process, we are particularly interested in the conditions under which information transmission is optimized. The key insight is that information transmission in our model is maximized when the output activity statistically preserves the input activity. That is, when , where denotes the total activity at time . This condition represents a critical balance where the network neither amplifies nor absorbs its input signals (on average), allowing for optimal propagation of information through the system.
Relating this back to our coupling strength , if is too low then signals will die out and information will be lost. Else, if is too high, the system will saturate, lose its ability to discriminate between different inputs, and enter an epileptic-like state. Thus, by examining the expected behavior of our system, we can identify the critical point where information transmission is optimized.
Taking the expected value over the random variables independently gives
Note that because are independent across neurons, we can compute expectations for each neuron separately, which preserves the mean-field dynamics.
To derive the network-level dynamics, we sum over all target neurons
Assuming the function does not saturate (valid when activity is sparse)
where we used the normalization condition .
The relationship reveals how information propagates through the network. At , we have , indicating that the expected activity at the next timestep perfectly matches the current activity. This represents a critical point where
- : Leads to information decay as activity gets absorbed by the network since . In this case, activity decays exponentially as .
- : The critical point where information is maximally preserved as increases. In this case, the expected activity in the next layer matches the current activity , and optimal information transmission occurs.
- : Leads to information saturation where activity amplifies until reaching a stable state of saturation where all neurons are active. In a similar way to case when , the system loses information about the initial conditions as time progresses.
This critical point at represents a unique balance where the network can maintain and transmit information without loss (on average), making it optimal for the transmission and processing of information. Another way of saying this is that at we are at the optimal point in which observing the activity at some time for maximally resolves our uncertainty about the initial condition . Hopefully I have explained this idea in enough ways to at least give some base-level intuition for why criticality might be advantageous for the brain.
Monte-Carlo Simulations
Now that we have mathematically formulated our model, we run a Monte-Carlo simulation to experimentally derive the phase-transition diagrams, compute the dynamic correlation length for varying values of , and study potential scale-free behavior at .
First, to study the phase-transitions of our model we simulate 10,000 realizations of neural activity on a 20x25 grid (neurons by time) using an initial condition of , and then computed the state of the model as the mean activity in the final layer (Figure 2). Doing so revealed an absorbing state for , where dynamics quickly get absorbed leading to zero activity in the final layer, and a saturating state for , where the activity quickly saturates all neurons in the final layer. As predicted by our theoretical results, a 2nd-order phase transition occurs at the critical value of where dynamics are optimally maintained without saturating or getting absorbed on average.

Figure 2: The state of the model (y-axis) given varying values of the control parameter J (x-axis). Notice that a 2nd-order phase transition occurs at the critical value of J=1 where dynamics are optimally maintained without saturating or getting absorbed on average.
To study the long-range dynamic correlation, we again simulate a 20x25 grid using an initial condition of across 10,000 realizations, and then used the following equation to measure the correlation of activity at time t from the initial condition as
This allows us to study how similar the activations are in layer from the initial conditions. If the activations are very different from then our correlation function should be much less than . Inversely, for close to the correlation function should approach for our experiment. As per our previous mathematical derivation, we would expect the maximum correlation value of to occur at the critical value . Running this experiment (Figure 3) empirically confirms this finding. One can see that at the critical value that .
Figure 3: The long-range dynamic correlation length (y-axis) given varying values of the control parameter J (x-axis). Notice that the correlation length is maximized at the critical value of J=1 representing critical dynamics.
Finally, inspired by John Beggs initial work on neuronal avalanches [1] [18], we study the scale-free properties of neuronal avalanches near the critical point. To do this, we simulate a grid of size 40x50 at the critical value , and set the initial condition to be . Then, we record the length that the information propagated (the length of the avalanche), and plotted its log-log distribution (Figure 4). If the dynamics are critical, we should expect to see a power-law distribution in the length of the avalanches. During implementation, there is the edge case of when the activity reaches the last layer (layer 50). In this case, we cannot determine the total length of the avalanche as the activity is not yet fully propagated. To handle this, we ablate out any cases in which the activity reaches the last layer (can be seen as clipping the distribution at the last layer). Furthermore, we can set up 2 controls with subcritical and supercritical dynamics, which in theory should not display scale-free behavior. The results can be seen below in Figure 4.
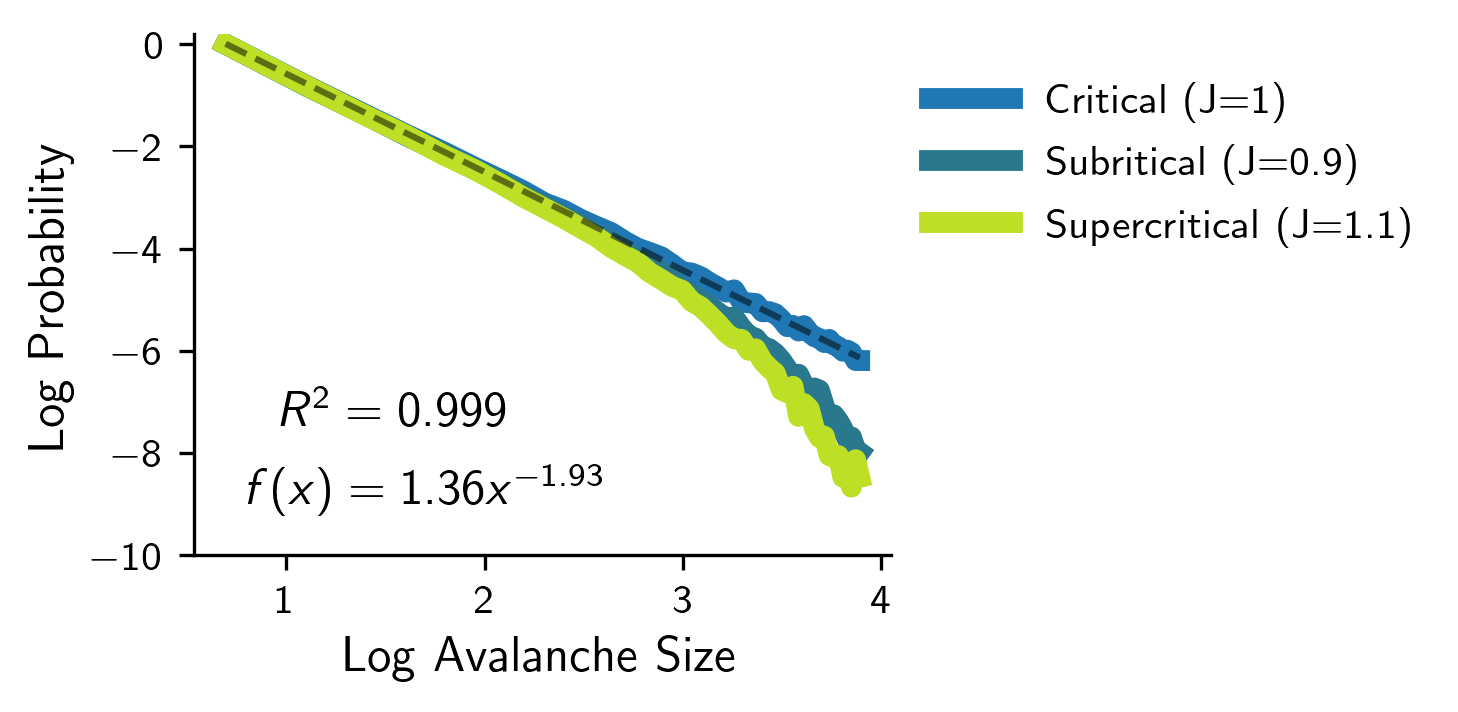
Figure 4: The log-log distribution of the length of the avalanches given three different values of the control parameter J at subcritical, critical, and supercritical dynamics. Notice that when J=1, we see a clear power-law distribution (linear line in log-log plot), and when J≠1, we see non-scale-free behavior (curved line in log-log plot).
Doing so revealed a clear power-law when , and non-scale-free behavior when . Furthermore, we computed the critical exponent when to be . You can look at the Marshall et al. paper [4] for a similar empirical study on simulated models.
Mean-Field Analysis
While the simulations revealed power-law behavior in the lifetime duration of avalanches with exponent , we can derive this analytically using a mean-field approximation of our branching process. In the mean-field limit, our branching model reduces to the classical Galton-Watson process, where each active neuron independently generates offspring according to a Poisson distribution with mean .
Let denote the number of active neurons at time . The dynamics are then
An avalanche beginning from continues until extinction, with length that we define as the first time such that . Formally, this is
For critical branching processes where the mean offspring equals 1, we know from early results in probability theory that the survival probability is
as , and where is the variance of the offspring distribution. See proposition 5 in section 1.4 of the U-Chicago notes on the Galton-Watson process for a full proof [22]. For , we have , yielding
The avalanche length distribution is then given by
Therefore, at criticality the avalanche-duration distribution follows a power law with critical exponent , which is consistent with the mean-field limit of the directed percolation universality class. Our numerical result of agrees reasonably well with this result (with finite-size effects on the 2D grid likely contributing for the small deviations). Experimentally, Beggs and Plenz [1] found critical exponents for the duration distribution of avalanches around in rat cortical slices. The critical exponent for the avalanche size distribution can likewise be derived, and can be shown for mean-field directed percolation to be , again matching experimental observations of in neural systems [1].
For , the power-law behavior we observed at criticality breaks down, as we saw in Figure 4. In the subcritical regime (), recall that activity decays exponentially and signals die out as . This exponential decay of the survival probability translates directly into an exponential distribution of avalanche lifetimes rather than a power-law, since the network is too absorptive to sustain the long-range cascades of neural activity characteristic of critical dynamics. In the supercritical regime (), the situation is reversed, where the network is so excitable that avalanches can have infinite lifetime with positive probability. Mathematically, the extinction probability satisfies , meaning some avalanches never terminate. This concentration of probability mass at infinity fundamentally prevents power-law behavior. Instead of scale-free dynamics, the network saturates too quickly and loses its ability to discriminate between different cascade sizes. Thus, power-law avalanche statistics uniquely emerge at the critical point , where the network balances between absorbing and saturating dynamics. This is exactly the regime where, as we showed earlier, information transmission is optimized. For references on this, again see the U-Chicago notes on the Galton-Watson process [22]
References
- Beggs, J., Plenz, D. (2003). Neuronal Avalanches in Neocortical Circuits. Link
- Tian, Y., Tan, Z., Hou, H., Li, G., Cheng, A., Qiu, Y., Weng, K., Chen, C., Sun, P. (2022). Theoretical foundations of studying criticality in the brain. Link
- Stringer, C., Pachitariu, M., Steinmetz, N., Carandini, M., Harris, K. (2019). High-dimensional geometry of population responses in visual cortex. Link
- Marshall, N., Timme, N., Bennett, N., Ripp, M., Lautzenhiser, E., Beggs, J. (2016). Analysis of Power Laws, Shape Collapses, and Neural Complexity: New Techniques and MATLAB Support via the NCC Toolbox. Link
- Morales, I., Landa, E., Angeles, C., Toledo, J., Rivera, A., Temis, J., Frank, A. (2015). Behavior of Early Warnings near the Critical Temperature in the Two-Dimensional Ising Model. Link
- Korchinski, D. (2021). Criticality in Spreading Processes without Timescale Separation and the Critical Brain Hypothesis.
- Jaeger, G. (1998). The Ehrenfest Classification of Phase Transitions: Introduction and Evolution. Link
- Heffern, E., Huelskamp, H., Bahar, S., Inglis, R. (2021). Phase transitions in biology: from bird flocks to population dynamics. Link
- Gros, C. (2021). A devil’s advocate view on ‘self-organized’ brain criticality. Link
- Beggs, J., Timme, N. (2012). Being Critical of Criticality in the Brain. Link
- Cocchi, L., Gollo, L., Zalesky, A., Breakspear, M. (2017). Criticality in the brain: A synthesis of neurobiology, models and cognition. Link
- Hengen, K., Shew, W. (2025). Is criticality a unified setpoint of brain function?. Link
- Rocha, R., Zorzi, M., Corbetta, M. (2024). Role of homeostatic plasticity in critical brain dynamics following focal stroke lesions. Link
- Shew, W., Yang, H., Petermann, T., Roy, R., Plenz, D. (2009). Neuronal Avalanches Imply Maximum Dynamic Range in Cortical Networks at Criticality. Link
- Ma, Z., Turrigiano, G., Wessel, R., Hengen, K. (2019). Cortical Circuit Dynamics Are Homeostatically Tuned to Criticality In Vivo. Link
- Hesse, J., Gross, T. (2014). Self-organized criticality as a fundamental property of neural systems. Link
- Santo, S., Villegas, P., Burioni, R., Muñoz, M. (2018). Landau–Ginzburg theory of cortex dynamics: Scale-free avalanches emerge at the edge of synchronization. Link
- Chialvo, D. (2010). Emergent complex neural dynamics. Link
- Beggs, J. (2007). The criticality hypothesis: how local cortical networks might optimize information processing. Link
- Kinouchi, O., Copelli, M. (2006). Optimal Dynamical Range of Excitable Networks at Criticality. Link
- Herz, A., Hopfield, J. (1995). Earthquake Cycles and Neural Reverberations: Collective Oscillations in Systems with Pulse-Coupled Threshold Elements. Link
- (). Branching Processes. Link
- Zimmern, V. (2020). Why Brain Criticality Is Clinically Relevant: A Scoping Review. Link
- Javed, E., Suárez-Méndez, I., Susi, G., Román, J., Palva, J., Maestú, F., Palva, S. (2025). A Shift Toward Supercritical Brain Dynamics Predicts Alzheimer’s Disease Progression. Link
- Landau, L., Lifshitz, E. (1980). Statistical Physics.
- Berlinsky, A., Harris, A. (2019). Statistical Mechanics: An Introductory Graduate Course.